Стандарт публикации моделей на базе пакетного менеджера nix
Предпосылки
Модель open source для распространения любых текстов, а не только исходных кодов программ
Любая информация в компьютере может быть представлена текстами на алфавитах определённой размерности. Некоторые тексты могут быть прочитанными людьми, остальные - только машинами. Развитие кибер-физических систем позволило использовать информацию не только для интерпретации людьми, но и для непосредственного материального производства в виде программ для устройств, а производство исходных текстов этих программ также претерпело значительные изменения в связи с появлением высокоскоростных сетей связи, позволяющих обмениваться информацией между множеством авторов. Так, в сфере разработки программного обеспечения появилось движение за открытые исходники (open source). Во многом благодаря тому, что в программах есть большой плюс - они могут быть применены, в отличие от аппаратных систем, всеми, у кого есть вычислительно устройство (ЭВМ) или компьютер. Именно этим обусловлено стремительно развитие ПО с открытым кодом - оно использует сетевые эффекты и мудрость толпы для получения более эффективных и быстро распространяющихся инноваций. В мире аппаратных систем данный подход пока не получил должного распространения, что обусловлено централизацией производств и невозможностью воспользоваться ими большими группами разработчиков. Опубликованная в общий доступ модель спутника не окажет почти никакого влияния на окружающий мир, потому что для её воплощения в жизнь потребуются редкое сырьё, высококвалифицированные рабочие и дорогостоящее оборудование. Однако стандартизация/унификация и удешевление средств производства постепенно решают эту проблему. Во многом именно этим обусловлена популярность 3D-печати. Изделия для 3D-печати могут быть произведены каждым владельцем принтера, тем самым создаются предпосылки роста популярности open source в мире "железа" - модель изделия для 3D-печати может быть передана по сети, произведена и приносить пользу. Даже в том случае, если модель не может быть изготовлена у непосредственно у пользователя, то всегда можно объединиться с другими пользователями вокруг одной потребности и заказать партию по минимально возможной цене (см. crowd supply). Постепенно появляются сообщества разработчиков вокруг контроллеров электродвигателей, роботов-манипуляторов, 3D-принтеров, биореакторов, специализированных АСУ и многого другого. Со временем станут появляться и более сложные системы с открытым кодом.
Сложности в распространении исходных файлов аппаратных систем.
В отличии от легковесных инструментов для написания и отладки кода в мире разработки аппаратных систем доминируют громоздкие CAD/PDM/PLM системы, которые, как правило, включают различные функции (в том числе контроль версий) в состав своих программных пакетов, делая затруднительным взаимодействие разработчиков между собой или ограничивая их какой-то конкретной экосистемой. Открытые стандарты обмена инженерными данными об изделиях (ISO/STEP) пытаются преодолеть эту проблему, но широкого распространения они так и не получили, потому что в проектах всегда содержится специфическая для конкретной CAD-системы информация, а также смешение разных предметных областей (domain) - свойства материалов, геометрия, технологическая информация. Наличие таких систем существенно ограничивает open source модель распространения - нет смысла в исходных файлах, если менять их можно только в специальном коммерческом ПО высокой стоимости. В мире разработки программного обеспечения такой проблемы никогда не существовало - стандартом обмена данными там всегда являлся определённый формат файла, который можно редактировать в любом текстовом редакторе, тогда как дополнительное удобство разработки программисты обеспечивали себе сами с помощью настройки окружения под себя. Таким образом наличие доступных средств проектирования является необходимым условием развития открытых проектов кибер-физических систем. Постепенно, такие средства приобретают черты чего-то пригодного к прикладной деятельности и возникают предпосылки для интеграции данных инструментов в полноценную инфраструктуру для разработки.
Управление зависимостями как инструмент коллаборации
Роль инфраструктуры для развития open source
git и сервисы, построенные вокруг него стали краеугольным камнем стремительного роста сообществ вокруг открытого кода. Это говорит о большой важности стандартов взаимодействия и, разумеется, git в какой-то степени является таким стандартом для текстовых файлов. Этот стандарт описывает способ взаимодействия большого количества разработчиков в децентрализованным способом, что очень важно для развития. Новым разработчикам не нужно уговаривать авторов исходной работы внести в неё изменения - они имеют возможность сделать копию - ветку(fork) - и внести изменения независимо от желания авторов, а git лишь обеспечивает способ безопасного слияния веток разработки. Это позволяет избежать в таких онлайн-сообществах свойственных корпоративному миру административной волокиты и бюрократии. Так, широко известный по книге "Социальная архитектура" популяризатор открытого ПО Питер Хинтьенс когда-то в своём проекте применял практику принятия запросов на изменения без ревью, несмотря на рискованность такой практики. Благодаря этому все новые разработчики чувствовали причастность к проекту и быструю обратную связь, что не менее важно. Появление инструментов непрерывной интеграции (continuous integration, CI) позволяет снизить риски при использовании такого подхода.
Роль инструментов управления зависимостями
Однако, одного инструмента контроля версии git оказалось недостаточно для сложных проектов разработки. Подход моно-репозитория, когда все компоненты сложной системы размещались в одном хранилище кода, упирался в административные барьеры (у репозитория один владелец) и технические возможности git. Новые функции git, такие как подмодули(submodules), не решили задачу управления зависимостями так, как это требует современная индустрия разработки. Вокруг каждого нового языка стали вырастать специальные инструменты управления зависимостями - npm, pip и многие другие. Это вывело возможности коллаборации на новый уровень. Например, сейчас в Github можно просмотреть в каких других проектах используется та или иная библиотека по Network Graph, что делает поиск аналогов простым и доступным. Ведь в open source зачастую важнее найти уже существующее, чем писать своё собственное, "изобретая велисипед". Тем не менее, специфичность отдельного пакетного менеджера для своих языков не облегчило процесс управления зависимостями в проектах, в состав которых входят программы на разных языках. К таким проектам относятся и кибер-физические системы (КФС), где используются слишком разнообразные инструменты разработки, форматы файлов и сборочные системы. Так сложилась потребность в независимом от языков и IDE способе управлять зависимостями, без которой проектирование много-сложных техническим систем затруднительно.
Пакетный менеджер общего назначения
В качестве способа управления зависимостями в моделях кибер-физических систем можно рассмотреть nix, который обладает рядом свойств, делающих его подходящим инструментом для этой задачи:
- Стремление к чистоте/детерминированности процесса вычисления/сборки/разворачивания
- Независимость от языков программирования и отдельных экосистем; подходит для работы не только с исполняемыми программами, но и с другими файлами.
- Использование git и некоторых других систем контроля версий в качестве базового слоя для хранения исходных файлов
Помимо децентрализованного git, ставшего стандартом индустрии для управления изменениями, и декларативного пакетного менеджера nix для управления зависимостями, в инфраструктуре может потребоваться хранение тех данных, которые предназначены для машин - это файлы для станков, скомпилированные бинарники, прошивки микроконтроллеров. С этой задачей справляется binary cache сервис, который входит в состав nix.
Базисное разбиение системы
Современная системная инженерия (например, согласно стандарту IEC 81346—1:2022) выделяет несколько типов декомпозиции систем: функциональное, конструктивное, пространственное, стоимостное. Функциональное разбиение строится по иерархии функциональных компонентов, которые именуются по их роли и могут быть реализованы различными физическими объектами. Конструктивное - по ссылкам на конкретные классы оборудования или их модели. Пространственное - по локализации в пространстве надсистемы. Стоимостное - по стоимости работ и оборудования.
Система всегда имеет воплощение в физическом мире, занимает место в пространстве, что нельзя упускать из виду при любой разработке, а потому в качестве базиса для разбиения систем и их отражения в структуре зависимостей nix должна использоваться модульная/конструктивная/синтетическая структура системы в виде дерева/графа с рёбрами типа является-частью (в англоязычной литературе по онтологии is-part-of). Дополнительным обоснованием этого решения является тот факт, что производство/сборка/модульный синтез осуществляется по конструктивным описаниям. По мере роста степени автоматизации возможна ситуация, когда машина сможет преобразовывать декларативное описание функций системы от человека в императивное описание способа построения, но при этом само преобразование не исчезнет - изменится актор, который будет это преобразование осуществлять.
Функциональное разбиение является более "субъективным" и часто формируется в контексте т.н. "сценариев использования". Например, в роли молотка может выступать множество предметов - да, в том числе микроскоп. Поэтому идентификация объектов по выполняемой функции может быть затруднительной.
В функциональном разбиении часто нет общепринятых стандартов описаний, тогда как в конструктивных описаниях их много. Например, форматы файлов для представления формы геометрических объектов в разных видах. Со временем эти форматы появятся и их можно будет сопоставить с конструктивными разбиениями, как это делается в IEC 81346—1:2022.
Одна и та же функция может быть распределена по множеству конструктивных компонентов - так, например, функция обмена данными с любым электронным устройством реализовывается с помощью
- разъёма для подключения кабеля
- проводящего слоя/дорожки на печатной плате
- аппаратного приёмопередатчика с обвязкой
- аппаратного периферийного блока микроконтроллера
- программного драйвера управляющей программы микроконтроллера
- программной библиотеки, реализующей протоколы взаимодействия.
Данная структура разбиения является инвариантом, которому должны соответствовать разнообразные описания. Дерево схем, дерево mesh-ей, дерево геометрических объектов, дерево документации, дерево модулей ПО - все они занимают место в пространстве и времени. Например, процессор является сложным изделием, которое можно описать одновременно как геометрическую модель, электрическую схему, исходный код программы. Каждое такое описание превращается в физическую сущность - механический корпус микросхемы, топологию проводящего рисунка или литографических слоёв, бинарный код программы, занимающий место в памяти - в ходе производства/компиляции/сборки, а введено в эксплуатацию в ходе размещения/деплоя/установки/инсталляции.
Стандарт публикации пакетов
Каждый компонент/объект/целевая система, потенциально занимающий пространство в реальном мире, имеющий временной экстент и который может быть потенциально использован повторно, размещается в отдельной директории или корне репозитория вместе с файлом flake.nix, который отвечает за воспроизводимость всего проекта кибер-физической системы и служит корневой конфигурацией системы, отвечающей за все поступающие извне зависимости и генерируемые артефакты. Имя каждого объекта является уникальным в контексте конфигурации и задаётся в nix-выражениях, из которых с помощью nix-функции mkDerivation формируются уравнения сборки. В выражении описываются необходимые для работы с ним инструменты/зависимости.
Связь между исходным и производным пакетом является зависимостью. Если компонент не может быть получен в результате вычисления чистой функции и требуется изменение состояния вручную, то к нему добавляется соответствующий patch из git-репозитория. Также компонент может быть задан полностью вручную, то есть формироваться без процесса сборки/компиляции/вычисления. В этом случае он должен быть задан через параметр src в функции формирования пакета или параметр inputs в flake.nix.
Структура корневой конфигурации репозитория в формате flake.nix
- inputs: Входными переменными flake.nix являются исходные файлы также содержащие
flake.nix, которые редактируются человеком в репозитории git и из которых создаются другие файлы с помощью вычислений. В момент генерации/сборки конкретные версии inputs фиксируются и записываются в flake.lock файл (подобно package/yarn.lock в npm/yarn), чтобы обеспечить воспроизводимость данного процесса независимо от окружения другого пользователя. Исходные файлы - по определению, те файлы которые создаются или редактируются человеком. К ним можно отнести как инженерные модели и исходные коды, так и другие описания - например, требования к системе, которые в дальнейшем могут быть проработаны в рамках эскизного и технического проектов. - outputs: выходные пакеты для целевой системы, исполняемые файлы -
bin,exe, представления 3D-моделей в видеBREP,STL,G-codeдля заданной конкретной модели принтера (который должен быть указан в качестве зависимости для данного артефакта), BOM-лист с составом деталей, PDF-версии чертежей, изображения, текстовые описания.
Структура внутреннего пакета/компонента КФС:
{ inputs ... }:. Пакет в nix является чистой функцией, аргументом которой является входное множество{ inputs }из других функций, которые необходимы для сборки и исполнения данного пакета (см. нижеbuildInputs,nativeBuildInputs), которые наследуются из корневой конфигурацииflake.nixи других nix-файлов. К ним могут относиться CAD, EDA, IDE, компиляторы, библиотеки, пакетные менеджеры, операционные системы, репозитории с пакетами типа nixpkgs, внешние зависимости.name. Уникальное имя компонента в пространстве имён проекта.src. Путь/url к исходным файлам - архиву, директории, конкретному файлу в репозитории. Для детерминированности сборки указывается с хеш-суммой от него.buildInputs. Зависимости времени исполнения . В случае программного обеспечения, если для работы исполняемого файла используется какая-то внешняя библиотека (в случае языка Си это *.so), то использующее этот исполняемый файл приложение не обязано знать об этой библиотеке, поэтому её следует указывать вbuildInputs. В случае с пакетов с моделями аппаратных систем такого рода зависимостями являются устройства, без которых невозможна работа данного модуля - например, источник энергии. Также к данному типу относятся зависимости времени исполнения, которые также передаются и по цепочке зависимостей дальше (downstream), то есть доступны при запуске пакетов, использующих данный пакет как зависимость. В nix они имеют названиеpropagatedBuildInputs. В случае программного обеспечения ими могут быть python-пакеты, которые используют зависимости своих зависимостей в runtime, а потому должны быть указаны вpropagatedBuildInputs. В случае с аппаратным обеспечением такого рода зависимостью может быть какой-то сервер, к которому обращаются отдельные модули.nativeBuildInputs. Зависимости времени сборки или производства - buildtime-зависимости, которые необходимы во время сборки, но не нужны во время исполнения. В случае с программным обеспечением это разнообразные компиляторы, библиотеки для тестирования, линтинга. В случае с аппаратным обеспечением этими зависимостями являются цифровые модели средств производств - станков, принтеров, оснастки, камер. ПодобноpropagatedBuildInputsдля зависимостей времени исполнения тут также естьpropagatedNativeBuildInputs- зависимости времени сборки, которые также передаются по цепочке зависимостей дальше (downstream), то есть доступны при сборке пакетов, использующих данный пакет как зависимость. В случае с аппаратным обеспечением такого рода зависимостями могут являться средства производства, единые для всех этапов технологического процесса - например, робот-манипулятор для сборки изделия или камера, распознающая все объекты в сцене. Создать окружение со всеми сборочными зависимостями можно с помощью комантыnix-shell. Runtime-зависимости в этом окружении будут отсутствовать, если явно не заданы вnativeBuildInputs. Поэтому, если какие-то зависимости нужны как во время сборки, так и во время работы, то их нужно указывать в обоих опциях.outputs. Каждое nix-выражение генерирует уравнение сборки пакета (derivation), в ходе которого формируются артефакты разных типов, которые выражены специальной формой вывода в виде файла или директории с файлами с заданной структурой. Параметрoutputsзадаётся в виде списка строковых значений. Например,outputs = [ "brep" "stl" "md" "png" "bin" ]для пакета сname = packageбудет преобразовано в ходе сборки в следующий набор пакетов:package-brep,package-stl,package-md,package-png,package-bin.
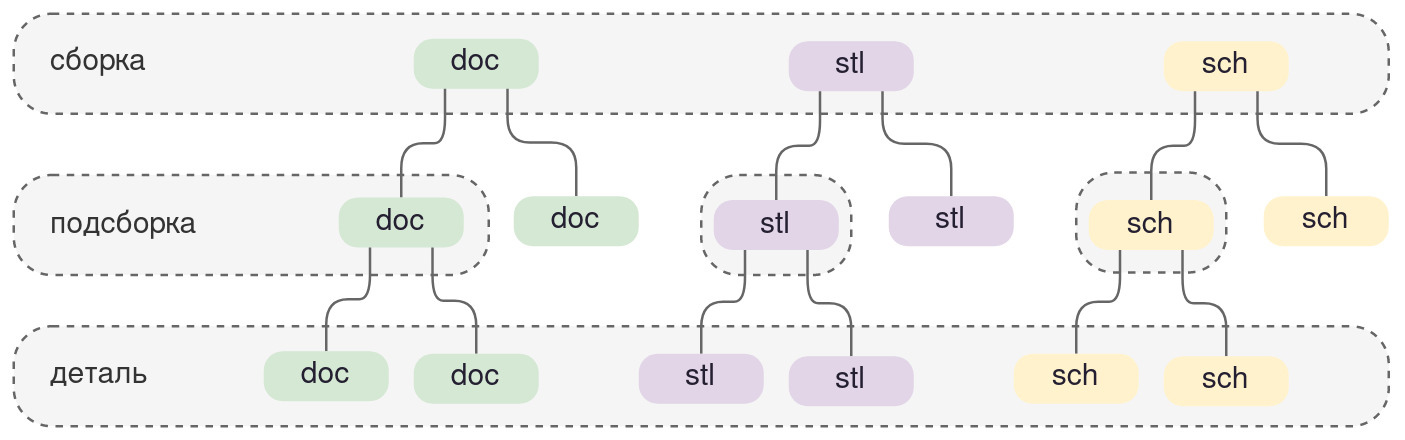
Компонент может быть описан множеством способов (views или viewpoints с точки зрения системной инженерии), поэтому каждый пакет хранит в себе информацию о методе вывода (view), что эквивалентно ассоциациям к типам файлов в операционных системах. Метод вывода является ссылкой на некоторое программное обеспечение (тоже пакет), выполняющее роль ПО для работы с данным артефактом. Инженер-электроник видит систему как принципиальную схему или spice-модель, конструктор - как набор тел геометрической формы, гейм-дизайнер видит как набор текстурированных mesh'ей для движка, программист как набор исходных кодов. Все эти способы представления прилагаются ко всем модулям, сама структура разбиения изделия на компоненты сохраняется. Структура разбиения позволяет получать агрегируемые и генерируемые автоматически пакеты документации с большим количеством уровней вложенности.
На рисунке ниже показана инвариантность разбиения в предметных областях схемотехники (sch-пакет), трёхмерного моделирования (stl-пакет), документации (doc-пакет) на примере сборки изделия.
Все артефакты, которые создаются в рамках сборки с помощью nix-выражений, можно проверить на консистентность или соответствие, так как хранилище nix (/nix/store) располагает всей доступной информацией для выбранной целевой системы. Наличие общего хранилища для всех артефактов проекта кибер-физической системы позволяет согласовывать (consistency) их между собой и, тем самым, эффективно управлять конфигурацией системы. Процесс согласования обеспечивают практики Непрерывной интеграции (Continuous Integration, CI), где изменения в каком-то из описаний проверяются на согласованность с требуемыми допусками. При этом мы разделяем непрерывную интеграцию, выполняемую людьми и непрерывную интеграцию, выполняемую с помощью автоматизированных вычислений.
Порядок вычислений и генерации производных артефактов
Компонент системы имеет условное графическое обозначение, геометрическую форму, материалы, вес, металлизацию, текстуру, параметры электрических соединений. Так, например, проектируя робота, необходимо опираться на модель материала (пластик, медь, железо, кремний), принципиальную эл.схему и некоторые другие параметры, которые будут влиять на результат вычисления. Результатом вычисления будет, например, вес или центр масс, который определён в зависимости от геометрических параметров изделия и свойств его материала:
- Получение веса, центра масс и параметров соединений с помощью геометрии детали и спецификации материала (
Geometry+Material->Weight,CenterOfMass,Joints) - Получение полигональной сети из геометрической модели (
Geometry->Mesh) - Получение итогового описания робототехнической системы в формате Universal Robot Desctiption Format из полученных выше весов и полигональных сетей (
Weight+CenterOfMass+Mesh+Joints->URDF)
Описания системы на разных системных уровнях и уровнях детализации описываются с помощью разных исходных файлов. Модель для игрового движка будет сверх-оптимизированной (до разумного предела) полигональной сетью (mesh) с PBR-текстурой для высокой производительности в симуляторе, в которой не будет никакой внутренней структуры, а только габариты и какие-то параметры поведения - например, триггер для запуска какого-то события. Эта модель будет связана чистой функцией преобразования с моделью инженерной, где будет отражена внутренняя структура системы. Если рассмотреть разработку твердотельных изделий, то часто полигональная сеть STL генерируется из первичной геометрической модели в формате BREP и геометрическое представление будет являться в данном случае первичным. Так как модели могут развиваться параллельно и независимо друг от друга, то конкретная последовательность вычисления может быть разной, так как нет какого-то пред-определённого конвейера, где за инженерной моделью следует модель игровая. Сначала может появиться игровая модель, а уже потом разработана конструкция изделия. То есть эти модели развиваются параллельно, описывая, тем не менее, один и тот же физический предмет. Тот факт, что отдельные модели могут быть получены друг из друга с помощью вычисления, не обязывает нас следовать этому порядку, описывая связи. Однако, очевидно, что из модели с высокой степенью детализации проще получить модель с низкой степенью детализации (абстрагирование, убираем ненужное в данном контексте), чем наоборот (рендеринг, инженерия, добавляем детали для лучшего соответствия действительности).
Например, в отношении видимых свойств объекта может быть реализована последовательность: Требования -> Рисунок на салфетке -> Эскиз художника -> Эскиз 3D mesh -> CAD модель изделия -> Mesh для рендера -> Mesh для игрового движка или симулятора. Однако, последовательность может быть и другой - например, прежде чем начать прорабатывать полную инженерную модель изделия, нам необходимо сделать эскиз для игрового движка, загрузить в виртуальную реальность, где бы пользователи могли ознакомиться с ней и понять удовлетворяет ли она их требованиям.
Пример. Артефакты и модели полигональной сети (mesh)
Ретопология - это процесс подготовки трёх-мерной модели для использования в игровых движках и симуляторов с целью обеспечить высокую производительность. По умолчанию, те mesh, которые генерируются автоматически из CAD-моделей, не отвечают требованиям игровых движков, содержат избыточную информацию.
Сейчас ретопология выполняется вручную, поэтому для неё создаётся отдельный репозиторий, который в качестве входных данных (зависимостей) получает сгенерированный алгоритмом mesh и грузит его напрямую из кэша на сервере, либо вычисляет самостоятельно по BREP-представлению, указывая mesh алгоритм в качестве зависимости. После этого он вносит изменения в этот mesh. Человек, осуществляющий подготовку модели для игрового движка или симулятора, ссылается на flake.nix репозитория редактора mesh'а и накладывает текстуру, указывая в качестве зависимости спецификацию материала, так как от неё текстура зависит. Таким образом, когда мы используем эту модель в библиотеке ассетов игрового движка, мы видим всё историю изменений, вплоть до изначальной геометрии.
Процедуры, производимые вручную могут быть проиндексированы, а полученные после индексации данные могут использоваться для обучения нейронной сети или каких-то алгоритмов. Для этого описанные процедуры должны быть специфицированы. Та же ретопология может быть специфицирована как функция, принимающая геометрию в BREP и возвращающая MESH. Если нам приходится вручную редактировать mesh после работы имеющегося несовершенного алгоритма генерации, то мы имеем цепочку: eval (BREP -> MESH) |> edit (MESH -> MESH), где количество полигонов уменьшено. Таким образом мы можем видеть общую картину степени автоматизированности процесса, а также механизм учёта вклада отдельных пользователей в дело обучения машины.
Итак, процесс ретопологии может выглядеть следующим образом. Мы ищем в реестре геометрических моделей нужную нам (по каким-то критериям) модель в нужном формате (например, BREP). Если над BREP нужно проделать предварительное вычисление, то нам нужно явно это указать - ссылкой на конкретный алгоритм. Дерево зависимостей может выглядеть следующим образом
- inputs: blender, sverchok, mesher (генератор полигональных сетей), brep flake, blend file с отредактированным mesh или конкретная последовательность действий над полигональной сетью(запись действий пользователя, типа rosbag или макроса) для удобства обучения
- outputs: stl, obj, dae, blend.