Машинное обучение
Каталоги проектов
Литература
- Учебник "Robotic Manipulation", изданный в MIT, предлагает вернуться "к истокам" от популярных нынче RL-методов - то есть к Control Theory. Часть с RL пока слабо проработана.
- Учебник "A Mathematical Introduction to Robotic Manipulation", изданный Калифорнийским технологическим институтом.
События
Conference on Robot Learning
Крупнейшая мировая конференция по обучению роботов (в 2020 году опубликовано 160 докладов и всё доступно для изучения)
IEEE International Symposium on Multi-Robot and Multi-Agent Systems
Multi-robot multi-agent конференция
Workshop on Closing the Reality Gap in Sim2Real Transfer for Robotics
Воркшоп по sim2real с научными публикациями. Официальный сайт
SAPIEN ManiSkill Challenge
Конкурс с открытым исходным кодом для выполнения задач манипулирования объектами.
Организации
Columbia Artificial Intelligence and Robotics Lab
Проекты лаборатории:
Decentralized Multi-arm Motion Planner
Децентрализованный планировщик движений для ансамблей роботов манипуляторов. Планировщик обучен на 1-4 манипуляторах, но при этом показал свою работоспособность на произвольном количестве манипуляторов. То есть является масштабируемым. В проекте использованы следующие python-библиотеки: pytorch, pybullet, numpy, numpy-quaternion, ray, tensorboardX. Для визуализации симуляций в Blender одним из авторов была разработана библиотека pybullet-blender-recorder. Доступны предварительно обученные модели.
AdaGrasp: Learning an Adaptive Gripper-Aware Grasping Policy
Разработка универсальной стратегии захвата для всех популярных моделей устройств механического захвата. Исследователи обучали модель на разных приспособлениях.
Fit2Form: 3D Generative Model for Robot Gripper Form Design
Fit2Form генерирует формы пальцев для параллельного захвата, которые обеспечивают более стабильный и надежный захват изделия по сравнению с другими алгоритмами проектирования захватов как общего назначения, так и для конкретных задач.
Исследования
Sachin Vidyasagaran '2020
Видео-обзор исследования по основным алгоритмам обучения с подкреплением Используемое ПО: OpenAI Gym Исследование проводилось на базе виртуальной среды FetchReach-v1 от OpenAI. Обзор решений для обучения роботов от OpenAI Результат(в случае с манипулятором): DDPG показал крайне низкую производительность - достижение приемлемого результата к 600 эпохе обучения, остальные три намного лучше
- Deep Deterministic Policy Gradient (DDPG) - 600
- HindSight Experience Replay (DDPG+HER) - 100
- Twin-Delayed DDPG (TD3+HER) - 150
- Extended Twin-Delayed DDPG (ETD3+HER) - 100
Liliana STAN, Adrian Florin NICOLESCU, Cristina PUPĂZĂ '2020 pdf
Машинное обучение для сборочных роботов. Обзор решений и подходов.
Вызовы обучения с подкреплением в робототехнике:
- Наличие большого количества степеней свободы у современных промышленных манипуляторов(6-7 DoF) приводит к т.н. "проклятью размерности" (взрывному росту числа возможных действий и состояний) и не позволяет использовать ряд алгоритмов. Возможные способы решения: выбор алгоритмов, нечувствительных к проклятью.
- Необходимость в большом количестве данных для обучения и длительность обучения. Создание баз данных на реальных объектах очень затратно, долго по времени и небезопасно. Возможные способы решения: создание проектов как KnowRob для сбора и аггрегирования данных многочисленных роботов в разных предметных областях, формирование баз данных.
- Проблема переноса алгоритмов обучения в другие среды и сценарии - Transfer Learning. Современные алгоритмы RL чувствительны к настройке гипер-параметров и требуют адаптации под каждый новый случай для достижения лучшей производительности.
- Обучение роботов в виртуальных средах способно компенсировать недостаток "реальных" данных, но оно чувствительно к недостаточной точности моделей как самого робота, так и его окружающей среды. Возникает проблема переносимости алгоритмов из симуляции в реальность - Sim-to-Real Transfer, выражающаяся в т.н. Reality Gap - расхождении в поведении движков физики и реального мира. Возможные способы решения: добавление шума в модели окражующей среды; domain randomization - добавление большего количества вариантов сред.
- Проблема безопасности. В ходе обучение параметры робота (от условий окружающей среды и компонентов) могут изменяться и процесс обучения может не сойтись. Возможный способ решения: использования низкоуровневых стратегий с использованием "мягких роботов"(?).
- Главный вызов в роботизации сборочных операций - надёжность, повторяемость, гибкость. Возможные способы решения: использование иерархической декомпозиции задач (Hierarchical Task Decompositions) и переиспользования навыков (Skill Reusability), когда большая задача разбивается на несколько маленьких, которые потом проще переносить на новые задачи.
- Вычислительная ресурсоёмкость. Решается развитием CPU/GPU/FPGA, паралеллизацией и это делает RL-подходы более применимыми на практике.
Главные стимулы для использования RL в робототехнике:
- изучение задачам, которые не могут быть напрямую запрограммированы
- оптимизация сложные задач, которые не имеют аналитических решений (известна функция затрат (например, снизить энергии для выполнения задачи)
- адаптация навыков к новым (ранее не встречавшимся) задачам.
Перспективные подходы к RL в робототехнике
- Self-Imitation Learning (SIL, paper, 21 October 2020). Алгоритм с единой стратегией использует эпизодические измененные прошлые траектории, т.е. ретроспективный опыт для обновления стретегии. Эксперименты показывают, что эпизодический SIL может работать лучше, чем базовые алгоритмы с единой стретегией (on-policy), достигая производительности, сопоставимой с современными алгоритмами с разделённой стратегией (off-policy) в некоторых задачах управления моделируемым роботом, обладая способностью решать проблемы с разреженным вознаграждением в условиях непрерывного контроля.
- Multi-Policy Bayesian Optimization (paper, 1 Apr 2021, github). Вариативное изменение параметров кинематики в ходе симуляции. Симуляция показала, что внесение изменений в кинематику во время обучения позволяет добиться выгод для переноса стретегии (policy transfer).
- Curiosity Based RL on Robot Manufacturing Cell (paper, 17 Nov 2020). Чтобы обучение с подкреплением оказалось успешным в робототехнике для планирования движений требуется ручная настройка вознаграждений. Для решения проблемы на гибкой производственной ячейке с роботом используется RL, основанное на использовании внутренней мотивации в качестве формы вознаграждения.
- SOft Data Augmentation (SODA) (paper, github, сайт) - метод, который стабилизирует обучение, отделяя увеличение объема данных от изучения политики. SODA - это общая структура (которая использует Soft Actor-Critic (SAC) в качестве базового алгоритма) для увеличения данных, которая может быть реализована поверх любого стандартного алгоритма RL.
- Fault-Aware Robust Control via Adversarial RL (paper, 30 Nov 2020). Предложена состязательная структура RL, которая значительно повышает устойчивость робота к повреждениям суставов и сбоям в задачах манипулирования. Это позволяет роботу быть в курсе своих рабочих состояний.
- Reachability-based Trajectory Safeguard (RTS) (paper, github). Используется параметризация траектории и анализ достижимости для обеспечения безопасности во время обучения стратегии. Метод RTS+RL демонстрируется в моделировании, выполняющем безопасное планирование отступающего горизонта в реальном времени на трех роботизированных платформах с пространствами непрерывного действия.
- Joint Space Control via Deep RL (JAiLeR) (paper). Глубокая нейронная сеть, обученная с помощью model-free RL, используется для сопоставления пространства задач (task space) с пространством соединений (joint space). Обучение модели показало, что этот простой подход позволяет достичь точности, сравнимой с точностью классических методов на большом рабочем пространстве, как в симуляции, так и в реальности. Преимущества этого подхода включают автоматическую обработку избыточности, ограничений на стык и профилей ускорения/замедления.
- Accelerating Reinforcement Learning with Learned Skill Priors (SPiRL) (paper, github). Для ускорения обучения с помощью имеющихся данных излагаемый в работе подход предполагает разбиение задачи на навыки и обучение по ним отдельно. Так можно сократить объём передаваемой информации от предыдущих попыток обучения.
Сочетание RL и Control Theory
Learning Robot Trajectories subject to Kinematic Joint Constraints (paper, github). В отличие от наказания за нарушение ограничений, этот подход обеспечивает четкие гарантии безопасности.
Motion planning for multi-robots - планирование движений нескольких роботов
- J. Kurosu, A. Yorozu, and M. Takahashi, “Simultaneous dual-arm motion planning for minimizing operation time”
- S. S. Mirrazavi Salehian, N. Figueroa, and A. Billard, “A unified framework for coordinated multi-arm motion planning,” Sep. 2018.
- J. P. Van Den Berg and M. H. Overmars, “Prioritized motion planning for multiple robots” 2005
Model-based RL from Signal Temporal Logic Specifications (paper). В этой статье предлагается выразить желаемое высокоуровневое поведение робота с помощью языка формальной спецификации Signal Temporal Logic (STL) в качестве альтернативы функциям вознаграждения/затрат. Используются спецификации STL в сочетании с model-based RL для разработки прогнозирующих поведение программ, которые пытаются оптимизировать выполнение спецификации STL в течение конечного временного горизонта:
- Формулируется процедура для обучения детерминированной прогностической модели динамики системы с использованием глубоких нейронных сетей. Учитывая состояние и последовательность действий, такая прогностическая модель создает прогнозируемую траекторию на заданном пользователем временном горизонте.
- Для оценки оптимальности прогнозируемой траектории используется функция затрат, основанная на количественной семантике STL, и оптимизатор черного ящика, который использует эволюционные стратегии для определения оптимальной последовательности действий (в настройках MPC - model predictive control).
_Темпоральная логика сигналов (STL) - это формализм темпоральной логики для определения свойств непрерывных сигналов. STL широко используется для анализа программ в киберфизических системах (CPS), которые взаимодействуют с физическими объектами. STL разработана в 2004 году (pdf). Есть свежая реализация C++ библиотеки с Python-биндингами для мониторинга спецификаций STL._
_Управление с прогнозирующими моделями (Model Predictive Control, MPC) — один из современных методов теории управления использующийся в основном в управлении производственными процессами. Является улучшением классического управления с отрицательной обратной связью, в котором учитывается предсказание поведения объекта управления на различные типы входных воздействий. Обратная связь в таких системах управления используется для корректировки неточностей, связанных с внешними помехами и неточностью математической модели объекта управления. Регулятор полагается на эмпирическую модель процесса для того, чтобы предсказать дальнейшее его поведение, основываясь на предыдущих значениях переменных состояния. Модель объекта управления обычно выбирается линейной._
Learning Stable Normalizing-Flow Control for Robotic Manipulation paper. В работе предлагается решение проблемы стабильности в RL-алгоритмах с помощью применения теории управления. Метод предназначен для того, чтобы в конечном итоге создавать детерминированные контроллеры с доказуемой стабильностью без потери эффективности обучения.
State-of-the-Art deep-RL алгоритмы в робототехнике
Основные классы алгоритмов:
- Discrete action space algorithms (DAS)
- Deep Q-Network (DQN)
- Deep Duelling Networks
- Normalize Advantage Functions
- Continuous action space algorithms (CAS)
- Stochastic continuous action space (SCAS)
- Stochastic policy gradient
- Deep actor-critic (with experience replay)
- Trust region policy gradient
- Neutral policy gradient
- Deterministic continuous action space (DCAS)
- Deep Deterministic Policy Gradient (DDPG)
- On-policy DPG
- Off-policy DPG
- Stochastic continuous action space (SCAS)
ACDER: Augmented Curiosity-Driven Experience Replay (paper). ACDER демонстрирует многообещающие экспериментальные результаты во всех трех основных сложных задачах роботизированной манипуляции и повышает эффективность выборки в пять раз по сравнению с ванильной DDPG+HER. Стратегии, обученные задачам "охват", "толчок" и "выбор и размещение", хорошо работают на физическом роботе без какой-либо дополнительной настройки.
Critic PI2: Master Continuous Planning via Policy Improvement with Path Integrals and Deep Actor-Critic Reinforcement Learning (paper). Подход сочетает методы оптимизации траектории, deep actor-critic RL и model-based RL. Планирование с помощью критика значительно повышает эффективность выборки и производительность в реальном времени.
Compose Hierarchical Object-Centric Controllers for Robotic Manipulation (paper). RL используется создания иерархических объектно-ориентированных контроллеров для задач управления. Подход имеет несколько преимуществ. Во-первых, объектно-ориентированные контроллеры можно повторно использовать в нескольких задачах. Во-вторых, композиции контроллеров инвариантны к определенным свойствам объекта. Наконец, использование структурированного пространства действий вводит значимые индуктивные предубеждения для манипулирования. Эксперименты показывают, что предлагаемый подход приводит к более целенаправленному исследованию и, следовательно, повышается эффективность выборки. Это позволяет обобщать нулевые результаты в тестовых средах и передавать моделирование в реальность без точной настройки.
Learning Force Control for Contact-rich Manipulation Tasks with Rigid Position-controlled Robots paper. Предлагаемый метод направлен на объединение управления силой с RL для изучения задач, связанных с контактами, при использовании роботов с позиционным управлением.
Алгоритм поиска последовательности сборки изделий с использованием прошлых результатов обучения (paper). Вычислительный алгоритм для поиска эффективной последовательности сборки и назначения работы рукам робота с использованием обучения с подкреплением.
Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: a Survey (pdf)
Авторы проанализировали, как multi-agent RL может преодолеть разрыв с реальностью в распределенных системах с несколькими роботами, где работа различных роботов не обязательно однородна.
GIGA - Grasp detection via Implicit Geometry and Affordance
GIGA - Нейронная сеть, которая обнаруживает позы захвата с 6 степенями свободы и одновременно с этим реконструирует трехмерную сцену. GIGA использует преимущества глубоких неявных функций, непрерывного представления с эффективным использованием памяти, чтобы обеспечить дифференцированное обучение обеим задачам. GIGA принимает в качестве входных данных представление сцены с помощью функции усеченного расстояния со знаком (TSDF) и предсказывает локальные неявные функции для понимания доступности и трехмерной занятости. Запрашивая имплицитные функции аффорданса с кандидатами в центры захвата, мы можем получить качество захвата, ориентацию захвата и ширину захвата в этих центрах. GIGA обучается на синтетическом наборе данных о хватании, созданном с помощью моделирования физики.
Инструменты машинного обучения
Библиотеки RL
- OpenAI Gym - Наиболее распространённая библиотека для обучения с подкреплением. Стандарт индустрии.
- Deepmind Acme - Вторая по популярности библиотека для RL
- Surreal - Open-Source Distributed Reinforcement Learning Framework by Stanford Vision and Learning Lab. Активно не разрабатывается.
- tf2rl - python-библиотека основных алгоритмов RL на Tensorflow2
- stable-baselines3 - набор надежных реализаций алгоритмов обучения с подкреплением в PyTorch, docs
Gym-UnrealCV
Реалистичные виртуальные миры для обучения с подкреплением. UnrealCV используется для связи Unreal Engine и Gym.
Flower
Фреймворк для federated learning (федеративное или распределённое обучение), который активно интегрируется в ROS (презентация RosDevDay'21). Ключевая идея состоит в том, чтобы локальные агенты отправляли на сервер не данные, а уже обновлённые параметры модели, которые потом агрегируются с помощью метода federeated averaging от Google (paper). В примере с pytorch существующий алгоритм обучения подключается к библиотеке Flower (указывается host:port сервера) и тиражируется на нескольких машинах, а на сервере задаётся количество раундов federated averaging.
robo-gym
Набор open source инструментов для распределённого машинного обучения на реальных и симулируемых роботах. Фреймворк состоит из двух частей:
- Серверной части, которая взаимодействует с реальным или симуляционным роботом. Реализована на ROS, Gazebo, Python.
- Части с окружающей средой, которая представляет OpenAI Gym интерфейс к роботу и реализует различные среды.
Ключевая особенность заключается в том, что части взаимодействуют между собой через сеть, что делает возможным реализацию обмена данными со множественными экземплярами частей как на одной машине, так и на нескольких.
Разработано JOANNEUM RESEARCH – Institute for Robotics and Mechatronics, Klagenfurt, Austria. Активно разрабатывается по сей день, но развитого сообщества нет - всего 2 контрибьютора - это авторы статьи.
В Paper также приведена сравнительная таблица(Table I, страница 7) фреймворков для глубокого машинного обучения роботов. Рассмотрены OpenAI Gym - Robotics Suite, DeepMind Control Suite, SURREAL Robotics Suite, RLBench, SenseAct, gym-gazebo-2, robo-gym. Показатели сравнения: количество форков, поддерживаемые роботы, количество задач, поддержка виртуального и реального железа, масштабируемость, используемая платформа симуляции. robo-gym
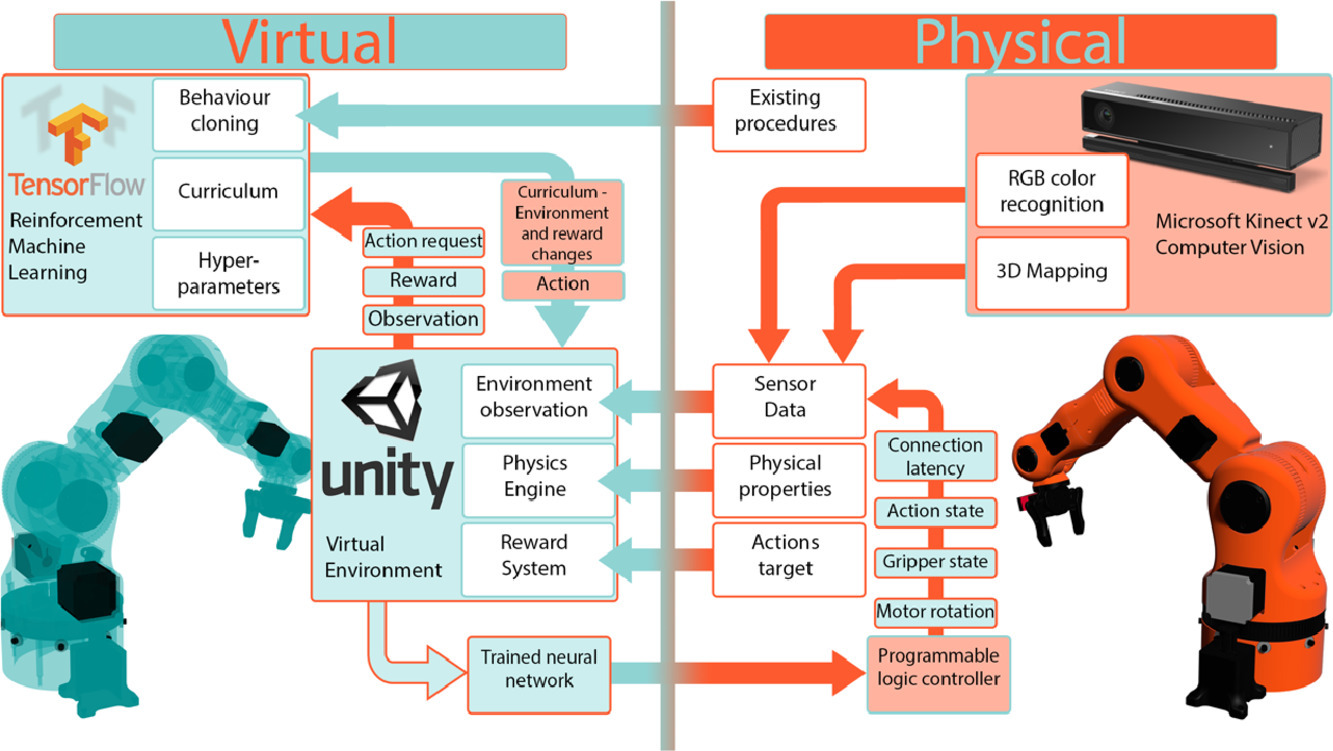
Unity ML Agents
Проект для обучения агентов на Unity, интегрирована с gym. Среды мультяшные, не очень фотореалистичные.
Gym Ignition
Github | Документация | Пример применения (видео)
Фреймворк для создания воспроизводимых виртуальных сред для обучения с подкреплением. В Gym-ignition представлена попытка создания унифицированного программного интерфейса как для реальных роботов и сред, так и для виртуальных.
Фреймворк состоит из следующих компонентов:
- ScenarI/O (Scene Interfaces for Robot Input / Output) - слой абстракции C++ для взаимодействия с виртуальными и реальными роботами. Этот слой позволяет скрыть детали реализации конкретного физического движка.
- Gazebo ScenarI/O: Реализация интерфейсов ScenarI/O для взаимодействия с симулятором Ignition Gazebo. Предоставляются python-биндинги набором функций, сопоставимым с популярными альтернативами - например, pybullet и mujoco-py.
- gym_ignition: python-пакет с набором инструментов для создания OpenAI Gym сред и обучения в них роботов. Пакет предоставляет такие абстрации как
TaskиRuntimeдля облегчения создания сред, которые могут запускаться прозрачно во всех реализациях ScenarI/O (различные симуляторы, реальные роботы, ...). Пакет также содержит функции для расчёта инверсной кинематики и динамики с несколькими физическими телами, поддерживающей плавающих роботов на основе библиотеки iDynTree. - gym_ignition_environments: Демонстрационные среды с образцовой структурой, созданные с помощью gym_ignition и gym-ignition-models.
OpenDR
Github | Справочное руководство
Целью проекта OpenDR является разработка модульного, открытого и непатентованного набора инструментов для основных функций роботов путем использования глубокого обучения для обеспечения расширенных возможностей восприятия и познания, таким образом отвечая общим требованиям приложений робототехники в прикладных областях здравоохранения, агропромышленного и гибкого производства. OpenDR предоставляет средства для связи приложений робототехники с программными библиотеками (средами глубокого обучения, например, PyTorch и Tensorflow) с операционной средой ( ROS ). OpenDR фокусируется на основных технологиях AI и Cognition для предоставления инструментов, которые делают роботизированные системы когнитивными, давая им возможность:
* взаимодействовать с людьми и окружающей средой, разрабатывая методы глубокого обучения для активного восприятия и познания, ориентированного на человека и окружающую среду,
* учиться и классифицировать, разрабатывая инструменты глубокого обучения для обучения и вывода в обычных условиях робототехники, а также
* принимать решения и получать знания, разрабатывая инструменты глубокого обучения для действий когнитивных роботов и принятия решений.
Проект реализует следующие основные категории задач для робототехники:
1. Инструменты распознавания человека и его деятельности, такие как распознавание лиц, жестов и эмоций человека, распознавание речи, обнаружение сердечных аномалий, оценки положения.
2. Инструменты обнаружения и сопровождения объектов в 2D и 3D, а также семантической и паноптической сегментации.
3. Инструменты обучения роботов навыкам движения и захвата.
4. Инструменты симуляции, такие как визуализация модели человека и фотореалистичный генератор многоракурсных изображений лица.
Также для взаимодействия с ROS разработан пакет opendr_bridge, который предоставляет интерфейс для преобразования типов данных и целей OpenDR в совместимые с ROS типы. Класс ROSBridge, реализующий данный интерфейс, предоставляет два метода для каждого типа данных X:
1. from_ros_X() : преобразует ROS-эквивалент X в тип данных OpenDR.
2. to_ros_X() : преобразует тип данных OpenDR в ROS-эквивалент X.
Большая часть пакетов представляет собой модули на Python'е, которые можно использовать раздельно по мере необходимости.
MoPA-RL
Website | Github | Paper | Video
Фреймворк сочетает преимущества обучения с подкреплением без модели (model-free RL) и планировщика движения (motion planner, MP) на основе выборки с минимальными знаниями о конкретных задачах. Для задач, требующих касания манипулятором или его приспособлением других предметов целесообразно использовать RL-policy, а в задачах, где нужно перемещение манипулятора в сложных стеснённых условиях, используется планировщик. Ключевая роль алгоритма состоит в том, что в ходе решения задач выбирается либо планировщик движения, либо прямое выполнение политики обучения с подкреплением. Тем самым достигается высокая производительность. В симуляциях использовался движок физики Mujoco.
SAPIEN - A SimulAted Part-based Interactive ENvironment
Фотореалистичная среда с большим количеством разнообразных объектов для взаимодействия с роботами-манипуляторами. Проект включает в себя cимулятор физических сред sapien (движок PhysX, assimp, ros-console-bridge, парсер urdfdom, алгоритмы для расчёта динамики сплошных тел pinocchio, мультиплатформенная библиотека для работы с OpenGL/Vulkan glfw), датасет, планировщик движений mplib на Python, gym-фреймворк для обучения роботов манипуляторов ManiSkill-Learn и Benchmark для него.
Совместный проект UCSD, Stanford и SFU. На базе проекта создан обучающий курс по RL в робототехнике, по завершению которого требуется выполнить тестовое задание, где два робота-манипулятора с рабочими органами-лопатками должны подбирать предметы с пола и складывать в коробку.
AirSim
Open source симулятор для автономных транспортных средств от Microsoft AI & Research. Интересен тем, что поддерживаются оба игровых движка для рендеринга - Unreal Engine и Unity(пока экспериментальная поддержка). Разработаны python-обёртки для OpenAI Gym и ROS.
Для поддержки URDF в AirSim разработан форк - UrdfSim.
RelMoGen
Leveraging Motion Generation in Reinforcement Learning for Mobile Manipulation | Paper
GraspNet
Открытый проект Шанхайского университета. Базовая модель нейронной сети для опознавания и захвата групп смешанных объектов. Много разнообразных датасетов.
Gibson Environments
Набор виртуальных сред (в основном жилые помещения для людей) для обучение мобильных роботов. Используется bullet и gym-подобный интерфейс для взаимодействия с агентом.
Nimble Physics
Движок предлагает использовать физику как нелинейность в нейронной сети. Форк популярного физического движка DART с аналитическими градиентами и привязкой к PyTorch. Многие симуляции, которые работали в DART, могут быть напрямую переведены в Nimble. Проект Stanford.
Обучение с подкреплением - определения и подходы
Обучение с подкреплением (ОП) - разновидность алгоритмов машинного обучения, наряду с обучением без учителя и обучением с учителем.
Алгоритм состоит в следующем:
- агент, руководствуясь стратегией (policy), воздействует (action, a) на окружающую среду с текущим состоянием (state, s)
- в ответ агент получает новое состояние окружающей среды s' и награду r
- на новом шаге агент меняет свою стратегию, чтобы максимизировать суммарное вознаграждение(value).
Отличие ОП и обучения с учителем
Цель обучения с учителем – научиться обобщать, располагая лишь фиксированным набором данных с ограниченным количеством примеров. Каждый пример состоит из входа и желательного выхода (или метки), так что реакция на выбор агента следует незамедлительно.
Напротив, в ОП акцент ставится на последовательных действиях, которые можно предпринять в конкретной ситуации. В данном случае единственное, что дает учитель, – сигнал вознаграждения. Какое действие правильно при данных условиях, неизвестно, в отличие от обучения с учителем.
Дилемма исследования(exploration)/использования(exploitation) в ОП
Агент должен совершать действия, которые с высокой вероятностью приведут к достижению цели (использование), но в то же время должен пробовать иные действия, чтобы другие части окружающей среды не остались неисследованными (исследование). Эту двойственность называют дилеммой (или компромиссом) исследования–использования, она призвана решить трудную проблему поиска баланса между исследованием и использованием окружающей среды. Она важна также и потому, что, в отличие от обучения с учителем, агент ОП может влиять на окружающую среду, т. к. вправе собирать новые данные, коль скоро считает это полезным.
Off-policy, on-policy
Off-policy - алгоритм ОП, где стратегия агента, воздействующего на среду (поведенческая стратегия), отличается от стратегии, которую обучают (целевая стратегия). Целевая стратегия фактически не используется для влияния на состояние среды.
On-policy - алгоритм, где воздействует на среду и обучается одна и та же стратегия. То есть стратегия обучается на тех же данных, которые генерирует.
Алгоритмы с разделенной стратегией(off-policy) менее устойчивы и их труднее проектировать, чем алгоритмы с единой стратегией, зато у них более высокая выборочная эффективность, т. е. для обучения нужно меньше данных.
Model-free (MFRL), model-based (MBRL)
Модель описывает поведение окружеющей среды, то есть может предсказать её состояние в следующем шаге. Если модель есть и известна(model-based), то можно использовать алгоритмы планирования. Модель может быть известна заранее или формироваться в ходе взаимодействия с окружающей средой.
Model-free делятся на
- Q-learning - алгоритм на основе обучения функции ценности действия); как правило это алгоритмы с разделённой стратегией(off-policy), чтобы сделать возможным обучение на базе предыдущего опыта, так как выборочные данные можно хранить в буфере воспроизведения.
- Policy gradient (градиент стратегии, метод оптимизации стратегии); как правило, это on-policy алгоритмы с единой стратегией. Актор-критик (actor-critic) - разновидность алгоритма оптимизации единой стратегии (актор) c одновременным обучением Q-функции ценности (критик). Поскольку алгоритмы исполнитель–критик обучают и используют функцию ценности, они классифицируются как алгоритмы градиента стратегии, а не как гибридные.
- Гибридные - сочетают обучение стратегии и функции ценности.
К model-based алгоритмам относятся
- чистое планирование
- встроенное планирование для улучшения стратегии и генерации выборки из аппроксимированной модели
- динамическое программирование - семейство алгоритмов, в которых модель используется для оценивания функции ценности. Смысл в том, чтобы разбить задачу на меньшие перекрывающиеся подзадачи, а затем найти решение исходной задачи, объединяя решения подзадач. Является одним из самых простых подходов. Подходит для вычисления оптимальной стратегии, поскольку имеется точная модель окружающей среды. Cложность экспоненциально возрастает вместе с увеличением числа состояний.
Выбор алгоритма ОП
Нет универсальных алгоритмов, все имеют как преимущества, так и недостатки. Наиболее значимые критерии оценки - устойчивость, выборочная эффективность, время обучения, простота использования, надёжность. Алгоритмы градиента стратегии более устойчивы и надежны, чем алгоритмы функции ценности. С другой стороны, методы функции ценности обладают лучшей выборочной эффективностью, поскольку это методы с разделенной стратегией и потому могут использовать предшествующий опыт. В свою очередь, алгоритмы, основанные на модели, лучше алгоритмов Q-обучения с точки зрения выборочной эффективности, но гораздо дороже с вычислительной точки зрения и работают медленнее.
Ссылки
Курс лекций по Reinfocement Learning от Deepmind